10 Good reasons to use Graph Databases
Because in the real world, things work connected
Esteban Agustin D'Amico

Let’s makepersistency evolve
Every time we are about to start a new project, we face an astronomic number of possibilities regarding the choice of languages, frameworks, libraries or platforms. But when we reach the persistent architecture definition phase, we always look into a small toolbox, that is basically composed of relational databases.
We basically spend most of our time discussing which ORM we should use, how we should map relations, thinking about normalization and denormalization, and many other activities that we have to deal with only because we are trying to fit a giant object world into the reduced alternatives offered by the relational world.
What if we could use a super world that includes all the alternatives… well, here is when the graph model and graph databases come up. Most of the problems we face are real world abstractions, and it happens to be that in the real world, things work connected. And quite often, a table does not look like the most adequate abstraction tool. Hereunder you can find 10 good reasons to prefer graph databases to relational ones.
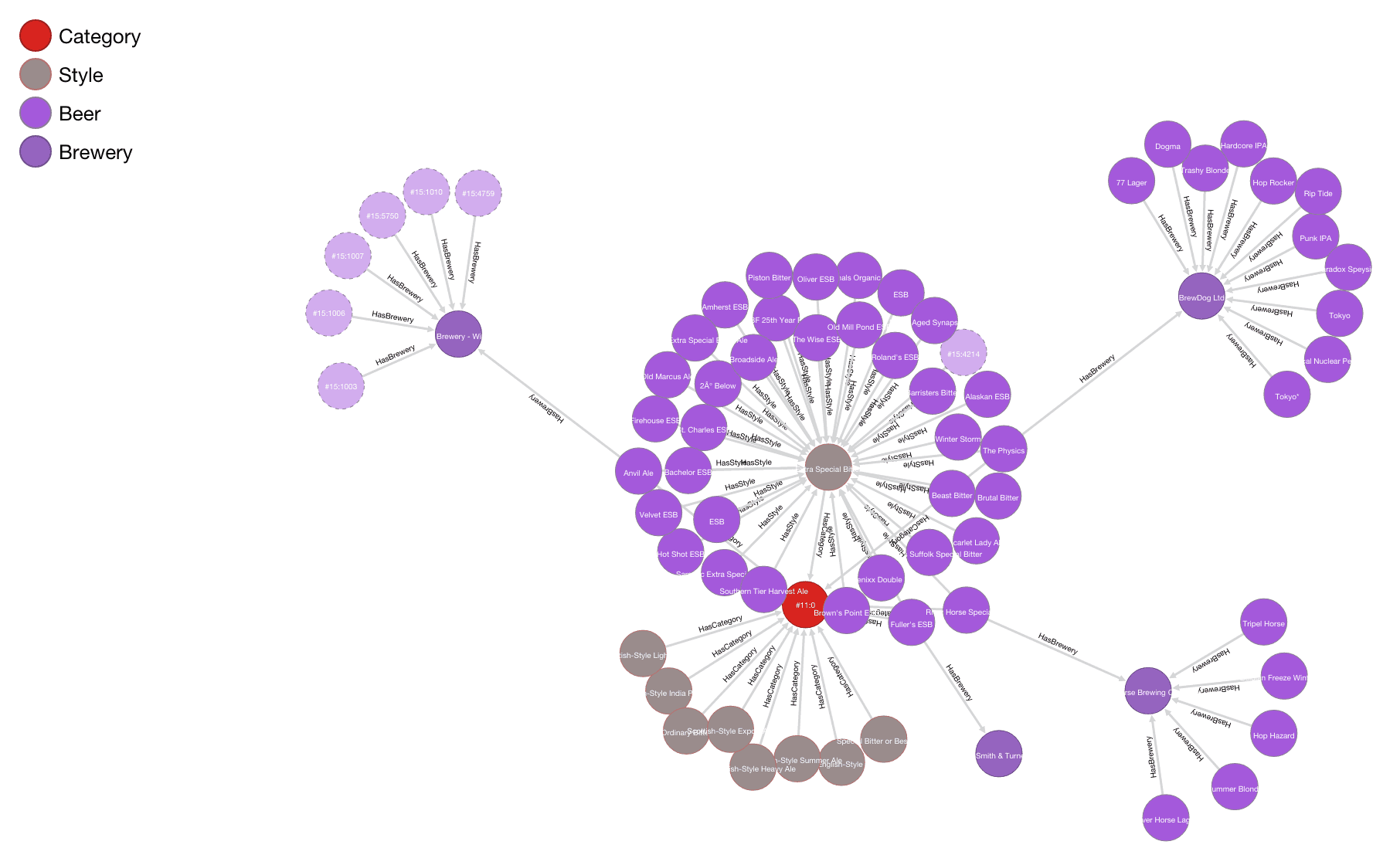
graph-oriented database graph representing nodes and connections
< Breweries and beers sample graph taken from Orient Studio />This graph enables us to easily infer relations. We can figure out which are the most popular breweries, get an idea of how a beer is produced produced and how many breweries produce a specific kind of beer, at a glance!
1. Graphs are everywhere
It happens to be that most of the areas we work on could be tackled a lot more easily using graphs rather than tables. Hereunder are some examples of fields of which graphs offer the most natural and intuitive representation:
- Social networks: friend of friends, job hierarchies, family modelling, etc.
- Logistic: searching optimal paths, considering connections, tracking routes, etc.
- Recommendations: track record, based on connections.
- Route finding: shortest path avoiding obstacles, enumerating alternatives, etc.
- Business: companies, locations, regions, transactions, etc.
2. Simple modelling
We have been taught to model using tables and relations, so we are used to it and know how to handle these models. Changing our perspective to think in a different way probably sounds like too much trouble, or even useless to most of us. But we should consider it, for the tables approach often turns out to be more complicated than we expected.
Let’s try to enumerate the steps in the design: When designing in a relational database context, we first need to understand the solution, and then to follow some tiresome steps: declare entities, discover and map intermediate tables, define foreign keys, normalize, denormalize, etc. When using graph databases we model the problem exactly as we understand it, which leads us to a cleaner model. If John is a friend of Peter, then we model it as follows:
[Person:John] (node) -> isFriendOf (edge) -> [Person:Peter] (node)
Just that, no intermediate table, no foreign keys…
3. Structured or non structured, that is the question…
Many times, we need to have uniformed data instances. If we are talking about persons for example, we expect to have the same properties for every person in the database. But the situation is different if we want to save documents, whose structure could change dynamically. Despite these differences, we want to be able to search in both, using a similar tool.
The static problem could be solved with no effort using a relational database. On the other hand, if we try to solve the non structured problem, we will face a lot of problems regarding how to store the information and how to search the saved data.
Luckily, there are many Graph database solutions that are hybrid like OrientDB and offer both approaches. Some even offer the structured, non structured and the mix solutions all-in-one.
4. Transactions in graph databases. Still possible?
Yes. Unlike some others NoSQL databases (MongoDB, CouchDB, etc), there are many engines that support ACID transactions, to make data saving reliable for any purpose. There is no need to manually support transactions since the engine will work it out!
5. Simple querying
Trying to solve recursive problems could be really annoying using relational databases. Let’s think, for example, about identifying friend of friends, or about granting inheritance… But if we tackle these problems using graphs, it’s just about traversing a graph.
6. SQL is not forbidden
The term NoSQL has been wrongly employed to define non relational databases. Contrary to what the common use of NoSQL suggests, there are many non-relational alternatives that offer some SQL adaptations (as OrientDB SQL) as query language. There are also many other simple languages like Cypher (Neo4j), Gremlin (a generic language for traversing graphs, used by Titan, OrientDB, InfinitGraph, etc) that are easy to use and straight to the point.
So if you doubted about adopting non relational databases because of the ramp up, stop doubting! Not only can we still use a SQL language to query the data, but there are also a lot of other incredibly powerful languages to make your queries pretty easy.
7. Queries directly from relations
In the relational database world, we can search only from tables, but not from relations. For instance, let’s imagine that we have the table Person, the table Company, the table Car and the table Address. If we want to know all the persons and cars and companies settled in a particular city, we will need to create three queries (or at least 3 subqueries) to get the result.
In the graph database world, the situation is totally different. We can query directly form any relation, even if we ignore the types of the connected endpoints. So with only one query, we can get all the livesIn relations, whether they be Car, Persons or Companies, it does not matter. Just that easy!
8. Performance… constant-time queries, could that be possible?
We have been working with relational databases since the 70’s, so we know the tips and the tricks to tune them. But as the relational database size grows smoothly, the response times grows as well. This means that every query will need to join more and more millions of tuples in memory to get the result subset.
Fortunately, graph databases don’t need to join anything. They use a simple index. And then from those nodes selected from the index O(log n), they traverse the edges to get the result set. So, believe it or not, we don’t need to worry about the collection/tables size!
9. Visualization, seeing beyond the data.
Understanding the data organisation using relational databases is really painful, we all know it. To get an idea of how many cars are owned by each person living in Manchester, we need to follow IDs of foreign keys and to create subqueries. This is due to the lack of native visualization tools.
In the graph model, navigating from Manchester to the cars is really simple and stems from the nature of the graph itself.
Many of the available products out there offer amazing tools to navigate the graphs. Besides that, there are great tools like Gephi that take visualization to an even higher level.

graph-oriented database
10. Qualified relations, for free!
Let’s suppose we want to model that John and Maria went to the same school. Well, that’s really easy, even in the relational world, we all agree on that. But now, let’s say that I need to add the date of the first time they went to that school… Ups! We need to change the easy schema to a new one, more complex, with an intermediate table. This could be really annoying! We need to migrate the schema, and change a lot of code to get it running again.
In the graph world, we could add properties to the relations on demand, so it would only involve adding the new startDate to the relations studyAt. Magic!
Conclusions
I hope this list helps us open our minds to graph databases. They are an amazing set of tools that we should always consider when starting a project. Using graph databases could make the difference between high-quality on-time delivered solutions and a big headache!
In future articles I will write about how to start a new project using a graph database, and some others on demand articles!