RAG Architecture & Vector Databases: What AI Agents Need to Succeed
Building AI agents that reason with real-time, accurate data starts with a RAG architecture. Learn how to select vector databases, optimize context retrieval, and scale pipelines for production.
Esteban Agustin D'Amico

Picture this: You built an AI agent for your car insurance company that can analyze unstructured data to see if a user's claim is valid or not. The agent reviews the picture, asks the driver to describe the issue, and contrasts the information against your policies. Then, it transfers the pre-approved cases to a human agent.
However, the AI agent operates solely on trained data, and you recently made changes to the collision policies. This is causing the tool to wrongfully deny some requests, leading to an increase in customer complaints.
This happens when the AI model relies solely on training data. Retrieval-augmented generation (RAG) architectures fix this by adding a retrieval layer that fetches the most relevant, current information before generating an answer.
However, implementing RAG isn't just flipping a switch. You have to decide how to chunk and embed data, which retriever type to use (vector, keyword, or hybrid), how to keep indexes fresh, and how to evaluate whether the retrieval actually improves answer quality. You also need to consider latency, token limits, reranking logic, and cost at scale.
Here, we cover how to implement an RAG architecture, which vector database to use, and the importance of adopting one. Let’s get started.
Table of contents
- Importance of RAG architectures in AI development
- How to build your RAG architecture using vector DBs
- How your data affects your AI models
- Where AI models go wrong: AI hallucinations
- The NaNLABS way: For when you don’t have the time to build RAG pipelines yourself
Importance of RAG architectures in AI development
RAG architectures not only improve your AI model credibility, but they’re also:
- Scalable and cost-efficient since you can augment models to serve multiple purposes as they gain access to more data through retrieval.
- More knowledgeable since RAG architecture patterns allow AI models to reason about information that wasn't in their training data.
- Less prone to AI hallucinations thanks to having access to authoritative sources that ground the model's responses in factual information rather than outdated or incorrect learned patterns.
- More reliable and trusted by users since retrieval allows users to trace AI responses back to specific, verifiable sources in your knowledge base.
- Easier to keep up to date by using RAG to update knowledge bases without retraining models.
- More secure because sensitive information stays within your controlled infrastructure rather than being baked into model weights.
The anatomy of RAG architectures (more than vector DBs)
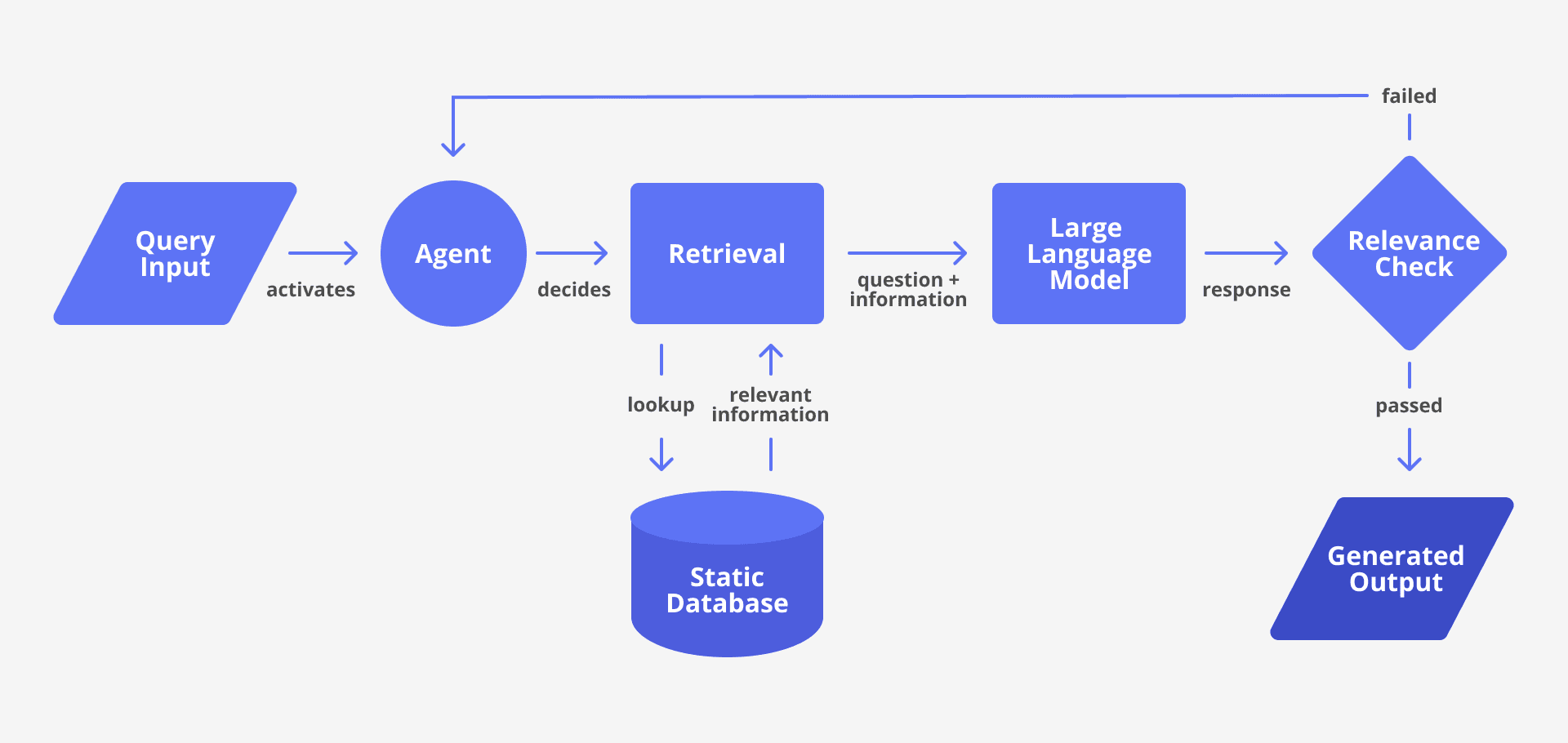
RAG architecture process map
Retrieval-augmented generation (RAG) is a process for improving the output of large language models (LLMs) by reviewing the information in a knowledge base, on top of training data. Only after the LLM confirms the right answers through retrieval, it writes a response.
Essentially, a RAG architecture combines a retriever and a generator component. The retriever is typically a vector or hybrid search system that fetches relevant documents based on the user query. The generator, on the other hand, is usually an LLM that uses the retrieved context to give a final answer (updated and accurate). The key stages include query embedding, retrieval from an external knowledge base, prompt construction with context, and generation.
Vector database selection criteria and trade-offs
Vector databases are a big part of the retrieval process as they allow you to store, handle, and query unstructured data as multidimensional vectors.
There are multiple vector DB providers, and finding the right one isn't just about performance benchmarks. You also need to consider query patterns, scaling requirements, persistence, durability, and integration complexity. Some options include:
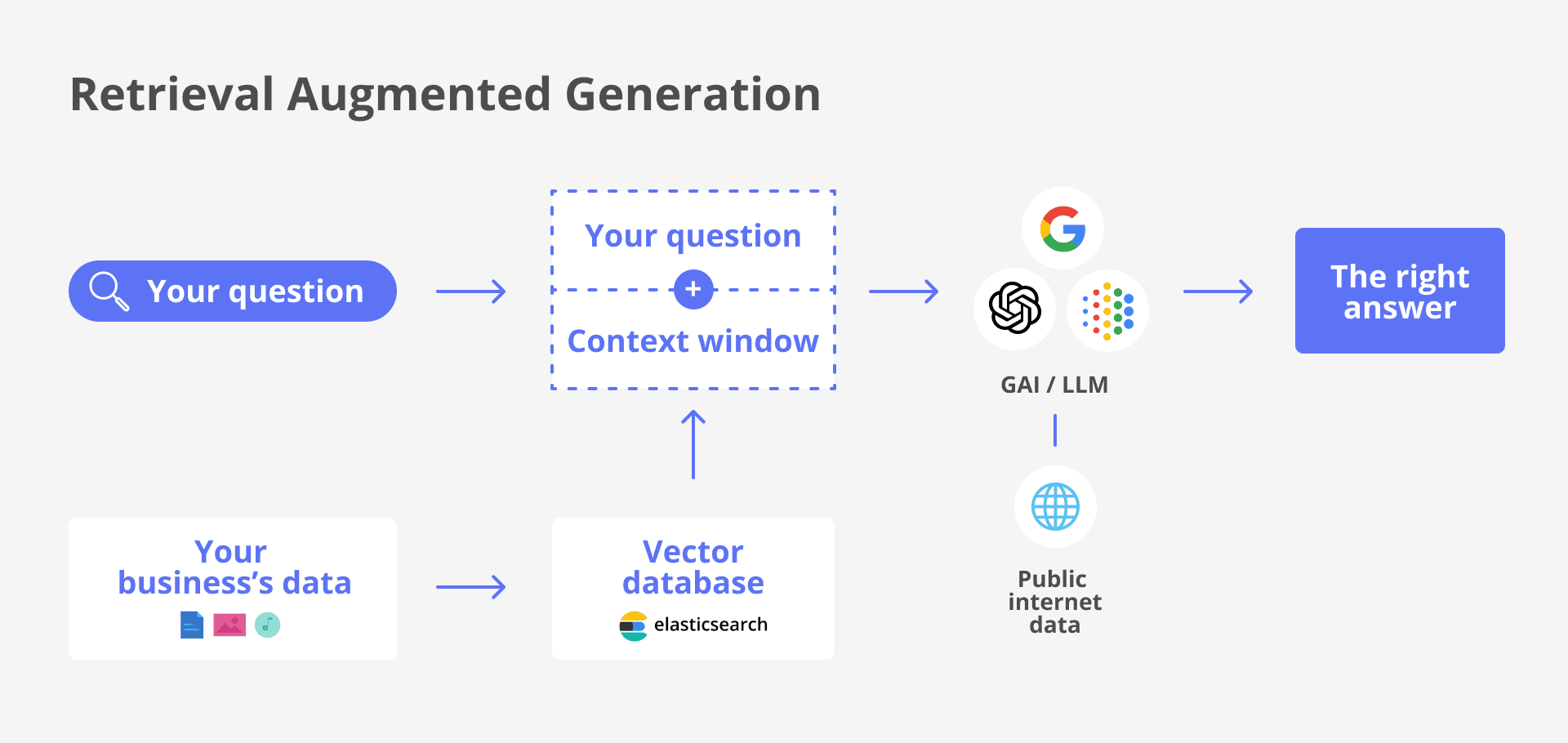
RAG architecture model using Elasticsearch as the vector DB
Definition: A distributed search and analytics engine designed for full-text search and log data analysis.
Why use it: Ideal for indexing and searching large volumes of structured and unstructured text data.
Cons: Managing large clusters can be complex and resource-intensive, which could lead to performance issues.
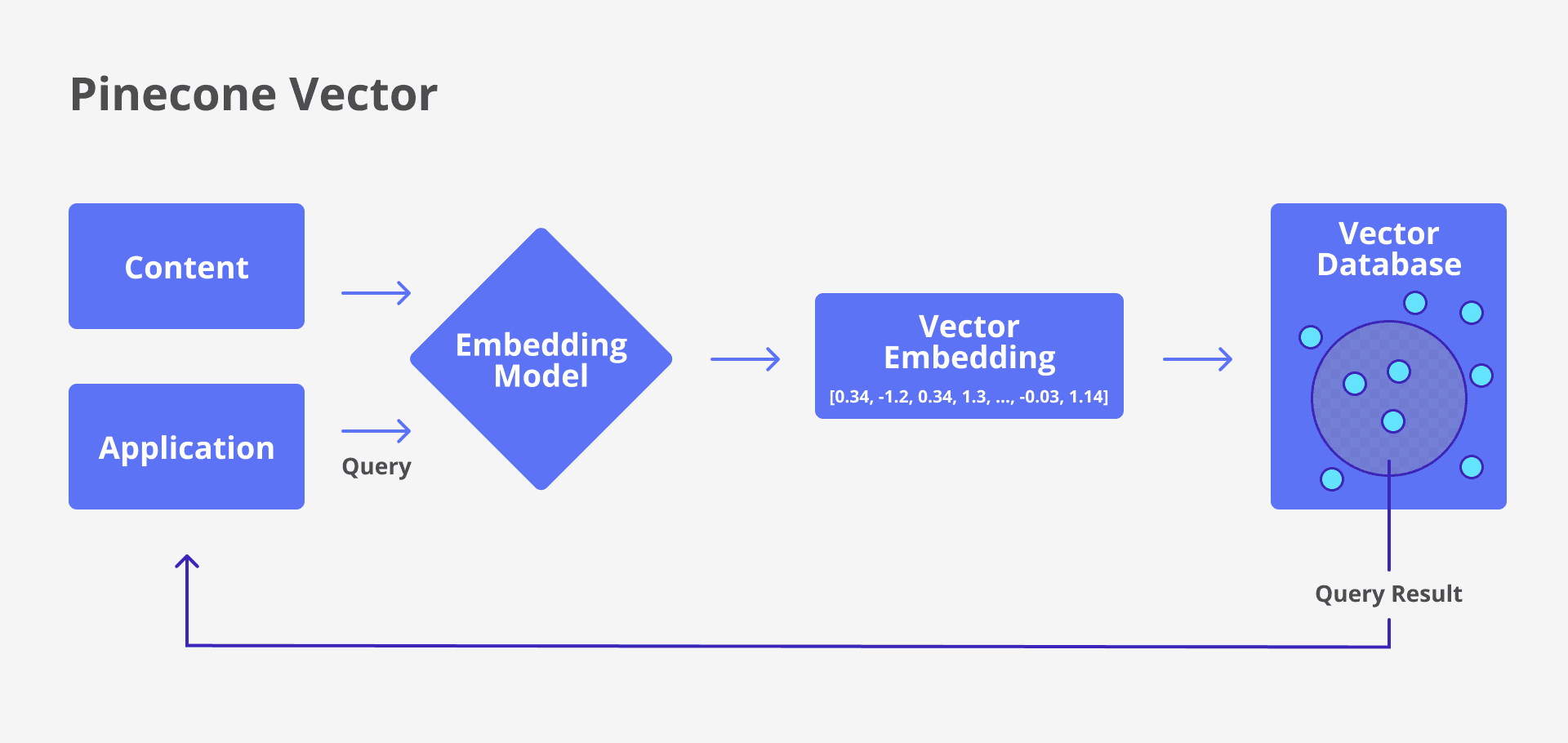
Pinecone vector embedding model
Definition: Pinecone is a managed vector database built specifically for similarity search in ML and AI applications.
Why use it: Provides fast, scalable, and accurate vector search with minimal infrastructure overhead.
Cons: It lacks robust native support for hybrid retrieval combining dense and keyword-based relevance scoring.
Code script from Weaviate
Definition: An AI-native vector database that supports smart and contextual search using ML models and hybrid queries.
Why use it: Combines vector search with keyword-based retrieval, metadata filtering, built-in ML model support, and flexible schema definitions. It’s highly adaptable for semantic and hybrid search.
Cons: Smaller ecosystem and community than other platforms. Also, performance and stability can vary with large-scale or complex hybrid queries, especially in self-hosted setups.
General note: Take this opportunity to check against your desired AI agent stack and see if there are any compatibility issues.
Embedding pipeline architecture patterns
Vector DBs are the first step to making unstructured data queryable. Embedding pipelines focus on semantic understanding as they:
- Handle chunking strategies that preserve context
- Implement deduplication to avoid vector space pollution
- Establish reprocessing workflows for when your embedding models evolve
- Manage multimodal content
- Maintain lineage for debugging
- Provide monitoring for embedding quality drift
Some ways to do this include batch processing, real-time data processing, Lambda architecture, and event-driven patterns.
Context injection strategies
How you inject retrieved context into your prompts determines whether your AI agent can reason effectively across multiple pieces of information. For example, imagine a customer asks your AI assistant about "pricing for Plate." The system pulls the most recent context, but doesn’t ask the user if they want information regarding the cloud or on-premise plan. Without this, the answer could be misleading. The more precise your context injection, the better your model can reason.
However, adopting simple concatenation of information leads to context overflow and attention dilution. Instead, you need intelligent ranking, context compression, and hierarchical injection strategies that maintain semantic coherence while staying within token limits.
But here's the critical insight: none of these components matter if the underlying data they're working with is fragmented, inconsistent, or poorly structured. That’s why RAG architectures are composed of multiple aspects.
Want help assessing if your stack is ready for RAG?
How to build your RAG architecture using vector DBs
To build a scalable and reliable RAG system, you need to address the state of your data quality and the model’s current retrieval and generation mechanics of retrieval. Here are four key phases to follow:
Phase 1: Data architecture assessment
Start by auditing the state of your data landscape. Assess the data quality, update frequency, and integration complexity to ensure your knowledge base can support accurate and fresh retrieval.
It’s also good practice to use real-time data for AI and establish baselines for retrieval precision, generation relevance, and system latency to evaluate performance later.
Phase 2: Unified data foundation
Adopt a data lakehouse or similar architecture that allows both structured filtering and unstructured semantic search. Then, modernize your pipelines so they support real-time or incremental updates, and implement validation gates to guarantee only high-quality data enters your system. Lastly, set up strong metadata management to enable efficient filtering and hybrid data retrieval.
Phase 3: RAG system implementation
Choose your retriever type (vector, keyword, or hybrid) based on the types of queries you get and business needs. Then, develop embedding pipelines with chunking strategies that preserve context and optimize reuse.
Continue by implementing retrieval optimization techniques like query expansion, reranking, and filtering to balance relevance, latency, and cost. Lastly, use smart context injection strategies to stay within token limits without losing coherence.
Phase 4: Optimization and scaling
Like everything in product development, the last step is never the last step. Continuously monitor the system performance with a special focus on retrieval latency, token usage, and generation quality. Then, build feedback loops to refine retrieval relevance and detect semantic drift. Plus, plan for horizontal scaling, embedding versioning, and cost control via caching and selective index updates.
How your data affects your AI models
Bringing back the introduction’s example, imagine your AI agent wrongfully approves a request because it’s following outdated policies. If you reverse the decision, you risk damaging the company’s reputation; but if you don’t, you lose money.
So, this isn't just about having "clean" data; it's more on having an AI-ready data infrastructure that's designed for semantic retrieval and cross-system reasoning. Let’s explore three ways data can hurt your AI models:
1. Fragmented data systems
Most companies have data scattered across dozens of systems: CRMs, ERPs, document repositories, databases, APIs, and legacy applications. Each system has its own data model, access patterns, and update frequencies. So, when a RAG system attempts to retrieve information across these fragmented sources, it may encounter many critical problems.
For example, let’s say you’re a charging point operator (CPO) who built an AI agent to anticipate potential EV charger failures. You want to dig into the data of an unusual session, but the POS has a different update frequency than the charger information, making it harder for your AI agent to highlight inconsistencies in real time.
2. Schema inconsistencies across data sources
Schema inconsistencies create semantic confusion that affects the entire RAG pipeline. For instance, one system stores "phone_number" as a string with formatting, another saves "phone" as digits only, and a third has separate fields for area code and number. Your embedding model will treat these as completely different concepts, making it impossible to retrieve comprehensive customer contact information.
3. Metadata quality
Poor metadata quality destroys your AI agent's ability to understand context and relationships. Without proper tagging, categorization, and relationship mapping, your vector database becomes a collection of isolated facts rather than a connected knowledge graph. This causes your AI agent to retrieve accurate information about a specific product but miss its relationship to complementary data.
Where AI Models go wrong: AI Hallucionations
Most AI models never see the light of day due to data problems. The algorithm works, the system is well built, but it’s designed on top of low-quality data. This leads to different issues, one of them being AI hallucinations.
AI hallucinations in models or RAG systems aren't random, they follow predictable patterns that come from architectural problems in your data foundation. These happen due to:
- Retrieval failure patterns in production systems. This is when your vector database can't find relevant information due to poor embedding quality, inadequate chunking strategies, or query-document semantic mismatches. Proper RAG pipelines allow AI models to say: I don’t have this information.
- Context confusion from poorly structured knowledge bases. If the retrieved documents contain contradictory information, lack proper attribution, or mix different levels of abstraction, the language model attempts to synthesize this conflicting information. This often creates fake but plausible-sounding responses.
- Semantic drift in multi-source data environments. Occurs when the same concepts are described differently across your data sources. Your embedding model may not recognize that "customer satisfaction score" and "CSAT rating" refer to the same metric, leading to retrieval gaps and incomplete context.
- Vector space contamination from dirty data. When your vector database contains embeddings generated from incomplete records, duplicate information, or data with quality issues, the similarity search may return semantically related but factually incorrect information. The language model then confidently generates responses based on this corrupted context.
The NaNLABS way: For when you don’t have the time to build RAG pipelines yourself
Building RAG architectures requires deep expertise in data engineering, machine learning operations, and system integration. Most teams either lack the skills, the time, or both.
At NaNLABS, we’ve built hundreds of data architectures, AI agent MVPs, AI and ML models, and RAG pipelines across SaaS, insurance, and EV industries. We understand that the real challenge isn't deploying a vector database, it's creating a unified data foundation that makes semantic retrieval actually work.
We combine our data engineering, AI development, and industry expertise to develop RAG pipelines that don’t get stuck in the prototyping stage. We design systems that reduce hallucinations by 80% on average and cut agent response latency in half, because trust and speed are mission-critical. Invite NaNLABS to join you in the co-pilot’s seat and build production-ready RAG pipelines.